for文の書き方について、何も疑問に思わずに次のように書いていませんか?
List list = new ArrayList();
//
// list.add()する処理
//
for(int i=0; i<list.size(); i++) {
//
// list.get(i)して何か処理する
//
}
果たしてこれは最適な書き方でしょうか?
for文の意味は次の通りです。
for(int i=0 /* 最初だけ処理する */; i<list.size() /* 毎回判定する */; i++ /* 毎回処理する */)
よく見ると、毎回判定する個所にlist.size()というメソッド呼び出しが存在しています。
これって、無駄です。
次のように書くと、より速いです。
List list = new ArrayList();
//
// list.add()する処理
//
int size = list.size();
for(int i=0; i<size; i++) {
//
// list.get(i)して何か処理する
//
}
ただこれだと、size変数がfor文のブロックスコープの外に出てしまっています。
そこで、次のように書くとカッコいいです。
List list = new ArrayList();
//
// list.add()する処理
//
for(int i=0, size=list.size(); i<size; i++) {
//
// list.get(i)して何か処理する
//
}
おなじみのint i=0の次にカンマで区切ってsize=list.size()を書きます。
ループカウンタiとsizeの型は必ず一致するので、この書き方がカッコいいです(主観です)。
ちなみにこの書き方が出来るのは、ループ中でlist.size()が変化しない場合のみです。
ループの中で追加・削除する場合はうまくいかないのでご注意ください。
実際に実行したときの処理時間の計測結果は次の通りです。
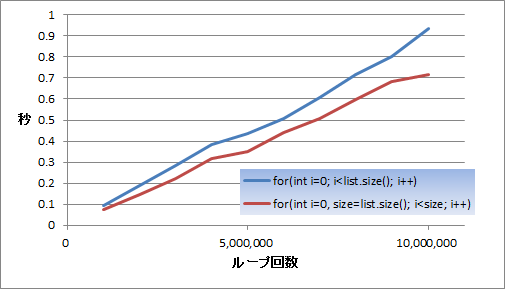
やっぱりsize = list.size()を1回だけ処理するようにしたパターンの方が速いです。
どっちをつかえばいい?
ぶっちゃけ、どっちでもいいと思います。そこまで処理時間も変わらないですし。
大量のデータを速く処理する必要がある場合はカッコいいやり方でどうぞ。
おまけ
計測に使ったJavaソースコードです。
import java.util.ArrayList;
import java.util.List;
public class ForLoopBenchmark {
public static void main(String[] args) {
benchmark(1000000);
benchmark(2000000);
benchmark(3000000);
benchmark(4000000);
benchmark(5000000);
benchmark(6000000);
benchmark(7000000);
benchmark(8000000);
benchmark(9000000);
benchmark(10000000);
}
private static void benchmark(final int count) {
System.out.print(count);
System.out.print("\t");
List<Integer> list = new ArrayList<>();
for(int i=0; i<count; i++) {
list.add(i);
}
long begin,end;
begin = System.nanoTime();
for(int i=0; i<list.size(); i++) {
list.get(i);
}
end = System.nanoTime();
System.out.print(end - begin);
System.out.print("\t");
begin = System.nanoTime();
for(int i=0, size=list.size(); i<size; i++) {
list.get(i);
}
end = System.nanoTime();
System.out.println(end - begin);
}
}
最後に
実は、このソースコードをそのままコピペして実行しても同じような処理時間にはならないと思います。
たぶん、意図した結果にならないです。その理由と、どうやって測定したかについて、後日記事にします。
2013/08/25追記
後日談、書きました。
→ジッとしてくれないJava VM